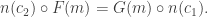From any category 

However, if we’re thinking of a category like Set, we just “formally reverse” the arrows: we define a morphism from A to B in Setop to be a function from B to A and define the composition of a morphism 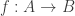

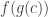
The point of using the opposite category is so that composition happens in the opposite order: if we want to wrap a function f in contracts, then the input contract should be applied before f and the output contract should be applied after f.
A profunctor is a functor of the form 
hom:Setop × Set -> Set
that takes a pair of functions 

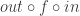
This profunctor produces a contract for a pair of functions with the given input and output contracts:
var pair = function (aIn, bIn, aOut, bOut) {
return makeProduct([hom(aIn, aOut), hom(bIn, bOut)]);
};
It’s the hom functor for Contract², the category of pairs of contracts and pairs of functions between them.
Here’s the hom functor for the free category on the complete graph with 26 nodes and self-loops. Objects are letters a-z; morphisms are strings beginning with the source node and ending with the target node. Composition is “overlapping” concatenation: we can only concatenate two strings where the last letter of the first string matches the first letter of the second string, and we “overlap” the matching letters so it only appears once: ‘cap’ + ‘ped’ = ‘caped’, not ‘capped’. The identity morphism on a letter is just the letter itself: ‘c’ + ‘c’ === ‘c’.
var overlap = function (strIn, strOut) {
str(strIn); str(strOut);
return function (s) {
str(s);
if (s.length >= 1 &&
s[0] === strIn[strIn.length-1] &&
s[s.length-1] === strOut[0]) {
return strIn.slice(0, strIn.length-1) + s + strOut.slice(1);
}
throw new TypeError('Wrong shape string.');
};
};
var tr = overlap('t', 'r');
tr('tubular') === 'tubular'; // passes the tr contract
tr('joe'); // throws a type error
var catran = typedConcat('cat', 'ran');
catran('tubular') === 'catubularan';
catMan('tamar') === 'catamaran';
The hom profunctor captures everything there is to know about a category; in Haskell, the interface Category is really for a hom profunctor.
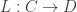 and
and  are adjoint functors if for all objects c in C and d in D,
are adjoint functors if for all objects c in C and d in D,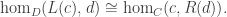
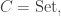
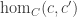 is the set of functions from the set c to the set c’,
is the set of functions from the set c to the set c’,  and
and  is the set of monoid homomorphisms from the monoid d to the monoid d’.
is the set of monoid homomorphisms from the monoid d to the monoid d’. PSet is the category of “pointed sets”—i.e. sets with a special chosen element called the “point”—and functions between them that map the point of the domain to the point of the codomain. Here,
PSet is the category of “pointed sets”—i.e. sets with a special chosen element called the “point”—and functions between them that map the point of the domain to the point of the codomain. Here, 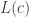 is the set c plus an extra point, while
is the set c plus an extra point, while  forgets which element of d was the special one.
forgets which element of d was the special one. where
where  is the category whose objects are natural numbers and there’s a morphism from
is the category whose objects are natural numbers and there’s a morphism from  to
to  if
if 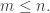 Here, the floor function forgets the fractional part of
Here, the floor function forgets the fractional part of 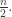
 where
where 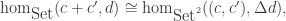 where Set² is the category of pairs of sets and pairs of functions between them, and
where Set² is the category of pairs of sets and pairs of functions between them, and 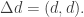 This is a categorification of the fact that in real numbers,
This is a categorification of the fact that in real numbers, 
 This is a categorification of the fact that in real numbers,
This is a categorification of the fact that in real numbers, 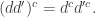
 This is a categorification of the fact that in real numbers,
This is a categorification of the fact that in real numbers, 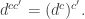
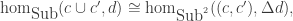 where Sub is the category of sets and inclusions (i.e. there’s a morphism
where Sub is the category of sets and inclusions (i.e. there’s a morphism 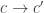 if
if  )
)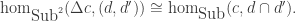
 Here Bool is the category with two objects F and T and an arrow from F to T—that is, there’s an arrow from one object to another if the one implies the other.
Here Bool is the category with two objects F and T and an arrow from F to T—that is, there’s an arrow from one object to another if the one implies the other. 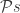 is the set of subsets of
is the set of subsets of 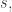 and
and 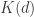 maps F to the empty set and T to
maps F to the empty set and T to 

 and
and  are isomorphic
are isomorphic  if there are functions
if there are functions 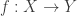 and
and 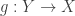 such that
such that
 , and
, and  .
.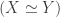 if there are functors
if there are functors  , and
, and  .
.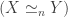 if there are functors
if there are functors 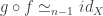 , and
, and 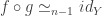 .
. if there are equations
if there are equations 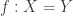 and
and 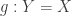 such that
such that
 is the equation
is the equation  and similarly for
and similarly for 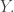
 and functors
and functors  and
and 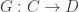 , a natural transformation
, a natural transformation 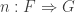 assigns to every object
assigns to every object  of
of 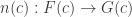 such that for every morphism
such that for every morphism 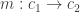 in C,
in C,